
Altı çekirdekli ve sekiz çekirdekli CPU’lardaki büyüme gerçekten görülmesi gereken bir şeydi. Temmuz 2011’de, Steam Hardware Survey’e göre oyuncuların yüzde 43,3’ü dört çekirdekli bir CPU’ya sahipti ve pazarın sadece yüzde 0,08’i sekiz çekirdekli yongalara ve yüzde 1,36’sı altı çekirdekli bir CPU’ya sahipti. Temmuz 2017’de oyuncuların yüzde 51,99’u dört çekirdekli CPU’ya, yüzde 1,48’i altı çekirdekli bir çipe ve yüzde 0,49’u sekiz çekirdekli bir çipe sahipti. Bugün, oyuncuların yüzde 31.11‘i altı çekirdekli yongalara ve yüzde 13,6’sı sekiz çekirdekli yongalara sahip. Bu, popülaritede sadece dört yılda 21 kat ve 27 kat artış ve Intel ile AMD arasındaki yenilenen rekabet bunun için teşekkür etmek içindir.
Maalesef çekirdek sayılarının artmasının da sınırları var.
Litografi artık bir zamanlar yaptığı performans iyileştirmelerini vermiyor; TSMC’nin 7nm -> 5nm -> 3nm’den öngördüğü performans ve güç tüketimindeki toplam kümülatif iyileşme, yaklaşık olarak 16nm -> 7nm’den küçülme ile elde ettiği iyileştirmelere eşittir. Intel ve diğer yarı iletken firmaları, bugün sahip olduğumuzdan daha verimli veya performans gösteren malzeme mühendisliği iyileştirmeleri, paketleme iyileştirmeleri ve yeni ara bağlantı yöntemlerini araştırmaya devam ediyor, ancak modern bir sistemde güç verimliliğini artırmanın en etkili yollarından biri, sonuç olarak, verilerin her yere taşınmasını durdurmaktır.
Onlarca yıl süren güç optimizasyonu ve sürekli gelişen litografiden sonra, bir bit veri üzerinde çalışmak için tüketilen toplam elektrik miktarı kabaca 1/3’tür. üzerinde çalışılmak üzere bellekten geri alma maliyeti. Rambus tarafından yayınlanan verilere göre, gücün yüzde 62,6’sı veri hareketine ve yüzde 37,4’ü hesaplamaya harcanıyor.
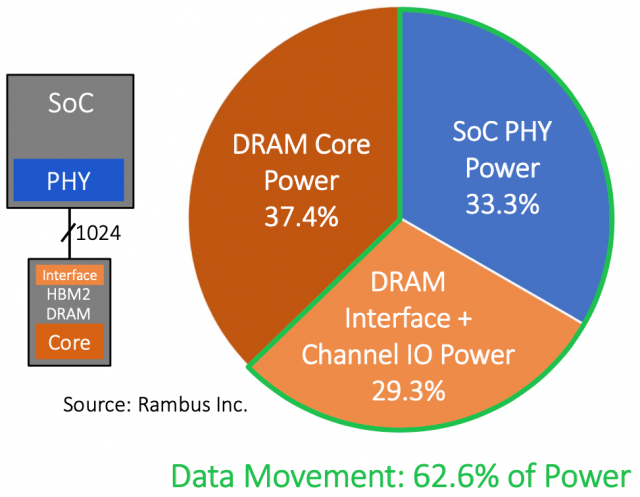
Rembus by Rambus
Bu sorunu çözmenin bir yolu hesaplamalı depolamadır. Fikir basittir: Hesaplamalı depolama, CPU’yu merkezi bir işlem birimi olarak ele almak yerine, işleme kapasitesini doğrudan depolama aygıtının kendisine yerleştirir.
Yakın tarihli bir makale, tamamen işlevsel bir prototip oluşturarak geleneksel uygulamalara kıyasla yerinde çalışan uygulamaların potansiyel güç tasarruflarını inceledi. Sistem, “farklı veri kümelerinde çok boyutlu FFT kıyaslamalarını çalıştırmak için” performansta 2,2 kat artış ve enerji tüketiminde yüzde 54 azalma sergiledi.
Verileri yerinde işleme fikrinin depolama dışında uygulamaları var; Samsung, bu yılın başlarında, HBM2’yi CPU yerine doğrudan hesaplamalar yapabilen bir dizi FP16 kaydıyla birleştiren bir bellek içi işlemci yığınını duyurdu. Bu durumda Samsung, güçte yüzde 70 azalma ile 2 kat performans artışı talep etti.
Bu teknolojiler emekleme aşamasındadır – büyük olasılıkla ana uygulamalardan yıllarca uzaktayız – ancak mühendislerin nasıl devam edebileceğini gösteriyorlar. litografi ölçekleme bocalarken bile sistem performansını iyileştirin. Bu fikirlerden tam anlamıyla yararlanmak, bir bilgisayarın içindeki veya bir SoC içindeki çeşitli bileşenler arasındaki ilişkiyi yeniden düşünmeyi gerektirecektir.
Merkezi İşlem Biriminden ‘Son Çare Hızlandırıcısı’na
I’ Hepimize bir noktada şuna benzeyen bir diyagram verildiğine bahse girerim:
Resim, Amila Ruwan 20, CC BY-SA 4.0
Bilgisayarlar şu şekilde düzenlenmiştir: Çoğu genel hesaplama görevinin CPU üzerinde gerçekleştiği ve CPU’nun sistem üzerinden veri akışı konusunda bir tür hakem görevi gördüğü fikri.
1990’ların sonlarında, yüksek performanslı bir depolama dizisine sahip olan herkes, bunu işlemek için bir RAID kartı kullandı. 2000’li yılların başlarından itibaren, CPU’lar, VIA gibi anakart yonga seti üreticilerinin yazılım RAID dizileri için desteği güneyköprülerine entegre etmeleri için yeterince güçlü hale geldi. AMD, Intel, Nvidia ve SiS gibi diğer şirketler de aynı şeyi yaptı, ancak dikkate değer bir farkla: VIA, son kullanıcı aynı zamanda bir SoundBlaster Live çalıştırıyorsa kurtarılamaz depolama hatalarına neden olan güney köprülerini göndermeye istekli tek şirketti.
CPU’lar daha güçlü hale geldikçe, mikro denetleyicilerden ve bir zamanlar bunları gerçekleştiren özel donanım yongalarından daha fazla işlev aldılar. Pek çok şirket için CPU’nun çeşitli görevleri yerine getirmesine izin vermek, Intel’e uygun veya onu aşabilecek özel silikon oluşturmaya devam etmeye yatırım yapmaktan daha ucuzdu.
Yıllarca süren optimizasyon ve sürekli üretim ve malzeme mühendisliği iyileştirmelerinden sonra, sorunun parametreleri değişti. Bilgisayarlar artık çok büyük veri kümeleri üzerinde çalışıyor ve petabaytlarca bilgiyi kurumsal düzeyde bellek veriyolu üzerinden ileri geri taşımak muazzam bir enerji kaybı.
Verilerin içinde taşınmasına daha az dayanan daha verimli bir bilgi işlem modeli oluşturmak ve CPU’dan çıkmak, CPU’nun hangi verileri işleyip işlemediğini yeniden düşünmeyi gerektirir.
SemiEngineering kısa süre önce veri taşıma maliyetini düşürme ve hesaplamalı depolama fikri hakkında bir çift mükemmel hikaye yayınladı ve Intel’de Optane çözümleri ve stratejisi kıdemli direktörü Chris Tobias ile konuştular. Intel’in Direct Connect Optane Kalıcı Belleği gibi bazı Optane ürünleri, herhangi bir tipik DRAM havuzundan çok daha büyük bir kalıcı DRAM bankası olarak kullanılabilir, ancak bu seçenekten yararlanmak için mevcut yazılımın değiştirilmesi gerekir.< /p>
Tobias SemiEngineering’e “Bundan yararlanmanın tek yolu yazılımınızı tamamen yeniden yapılandırmaktır” dedi. “Şu anda yaptığınız şey, hesaplama depolamasının iyi bir iş çıkardığı bu [bir uygulama] parçasına sahip olduğumuzu söylüyorsunuz. Bu sorumluluğu sunucu yazılımından alacağız ve ardından bu tek parçanın birden fazla kopyasını SSD’ye ekleyeceğiz ve hepsi bu parçayı burada yürütecekler. Birilerinin sunucu yazılımını SSD’lere giren parçaya ayırması gerekiyor.”
Bu tür verimlilik iyileştirmeleri, çipin zamanının çoğunu performans harcamasına izin vererek CPU yanıt hızını ve performansını iyileştirecektir. yararlı işler ve başka bir yerde daha iyi ele alınabilecek G/Ç isteklerine katılmak için daha az zaman.
Kullanıcılar, kıyaslamalar gerçek bir hız artışını doğrulamasa bile, M1 Mac’lerin geleneksel Intel cihazlarına göre daha hızlı kullanıldığını bildirdi. Nvidia’nın 10 yıl önceki Atom tabanlı Ion netbook platformu, gecikmeyi iyileştirmenin (bu durumda, görüntüleme ve kullanıcı arayüzü gecikmesi) bir sistemi gerçekte olduğundan çok daha hızlı hissettirdiğinin bir başka tarihi örneğidir.
Gerektiren hiçbir şey yok. Depolama yığınının toptan yeniden tasavvur edilmesi, yakın zamanda tüketici ürünlerini vuracak, ancak uzun vadeli iyileştirme potansiyeli gerçek. Bilgisayar endüstrisi tarihinin çoğunda, bir CPU’nun döngü başına gerçekleştirdiği iş miktarını artırarak performansı iyileştirdik. Hesaplamalı depolamanın ve iş yüklerini CPU’dan taşımanın diğer yöntemlerinin zorluğu, CPU’ya döngü başına daha az iş vererek diğer görevlere odaklanmasını sağlayarak performansını artırmaktır.
Bu modelde, CPU’nun performansını artırmaktır. CPU biraz daha hızlandırıcı gibi olurdu. Spesifik olarak, CPU son çarenin “hızlandırıcısı” olur. Bir iş yükü karmaşık, seri hale getirilmiş veya GPU’ya ve/veya AMD ve Intel’in bir gün gönderebileceği herhangi bir AI donanımına uygun olmayan dallı, öngörülemeyen kodlarla dolu olduğunda, tam olarak bu konuda uzmanlaşmış CPU’ya yönlendirilir. tür sorun.
2010’ların ortalarında, x86 güç verimliliğini tanımlayan 0W yarışıydı ve Intel ve AMD, boşta kalan gücü azaltmaktan önemli ödüller aldı. Önümüzdeki on yıl içinde, CPU’nun ne kadar bilgi taşıyabileceğini vurgulamak yerine ne kadar veriyi işlemekten kaçınabileceğine odaklanan yeni bir yarışın başladığını görebiliriz.
Şimdi Okuyun< /strong>:
Sıcak ve Yavaş DRAM, Exascale ve Ötesinde Büyük Bir EngeldirIntel Bunu Resmi Hale Getiriyor: Hibrit CPU Çekirdekleri Alder Lake ile GeliyorAMD Kendi 25×20 Hedefini Aşar, Ryzen Güç Verimliliğini 31x Artırır.




